Reasoning about Avro compatibility with Alloy
After I learned the basics of Alloy, I wanted to use it for anything practical. Well, maybe not exactly practical, but more grounded in what we consider "software engineering".
Since I read quite a lot about compatibility modes of various data formats at that time, I decided to try to describe Avro compatibility modes in Alloy. Or at least one aspect of those compatibility abilities, which in the scope of this article will be backward compatibility.
Before diving in, let's clarify some terminology. According to clear and concise Martin Kleppmann's definition, backward compatibility is:
The ability of newer code to read data that was written by older code
This stands in contrast to what forward compatibility is:
The ability of older code to read data that was written by newer code
The question that inspired me to write this post struck me when I was studying documentation of Confluent Schema Registry, a service for capturing how schemas (originally Avro, but also others) evolve within your organization over time. Its documentation contains the table summarizing various compatibility types available in that product. The thing that caught my attention is the distinction between BACKWARD and BACKWARD_TRANSITIVE.
Such demarcation looked surprising to me given their identical definition of allowed changes. For both compatibility types, the allowed changes are:
- Deleting fields
- Adding optional fields
Here we arrive at the question motivating this article: does BACKWARD imply BACKWARD_TRANSITIVE? If not, why?
To answer this question, I could have thought it over, as in "use my brain". But instead, I decided to use my brain to build a simple model in Alloy first, which in turn will reason about the problem for me. Perhaps an overkill, but also a fun exercise.
The plan
The end goal of this exercise is to understand whether a property of backward compatibility (in the sense of Avro's capabilities described here) is transitive. It's a biased question: thanks to the distinction drawn in docs, I can already be pretty sure the answer is negative. Therefore, what I am really looking for is a counterexample. For that purpose, Alloy sounds like a perfect tool.
Hence, the plan:
- encode basic terms in Alloy: attributes, entities
- generate several examples schemas to verify that constructed model is sensible
- define in Alloy what deleting and adding fields to schema means
- describe property of transitivity in Alloy
- let Alloy find a counterexample
Alloy model
Let's start with specifying that an entity is a set of attributes, each attribute is either a string or an integer, and an attribute can be optional. I am intentionally describing only a small subset of Avro, just enough for my use case.
It may look like this in Alloy lingo:
sig AttributeName {}
one sig Optional {}
abstract sig Type {}
one sig Str extends Type {}
one sig Integer extends Type {}
sig Attribute {
name: AttributeName,
optional: lone Optional,
type: Type
} {
// To avoid orphaned attributes
some e: Entity | this in e.attributes
}
sig Entity {
attributes: some Attribute
} {
all a1, a2: attributes | a1 != a2 => a1.name != a2.name
}Let's generate some example schema with run {} for 3 but 1 Entity:
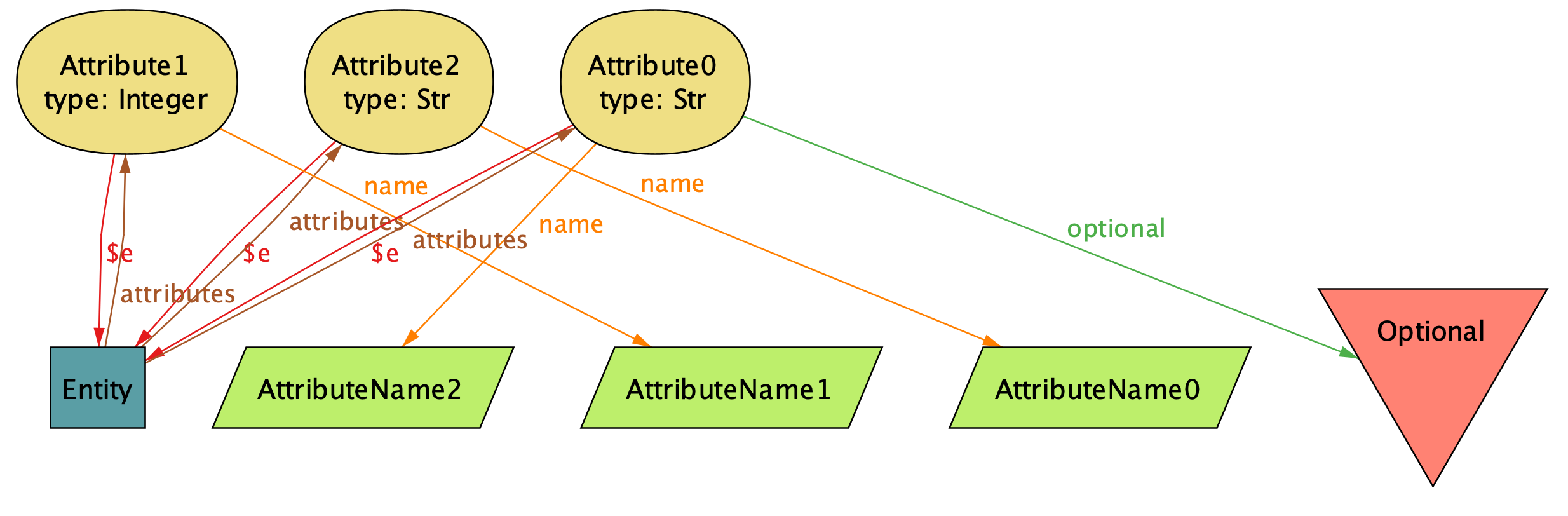
Making sense of diagrams generated by Alloy, while not difficult, takes some time to get used to. I covered that topic in my guide to Alloy, so I'll move to the interpretation without any in-detail explanation.
In short, the above diagram corresponds to such an Avro type:
{
"type" : "record",
"fields" : [
{"name" : "AttributeName0", "type" : "string"},
{"name" : "AttributeName1", "type" : "int"},
{"name" : "AttributeName2", "type" : ["null", "string"]}
]
}Sorry for the inconsistent terminology for types between the picture and the Avro schema. Unfortunately, both string and int are reserved words in Alloy, so I had to resort to Str and Integer in Alloy.
The example schema looks reasonable, so I can proceed to the next part. I'll start with defining what deleting an attribute means:
pred delete_attribute[new, old: Entity] {
new != old
new.attributes != old.attributes
one a: Attribute | old.attributes = new.attributes + a
}Let's generate some diagrams with run delete_attribute for 3 but exactly 2 Entity:
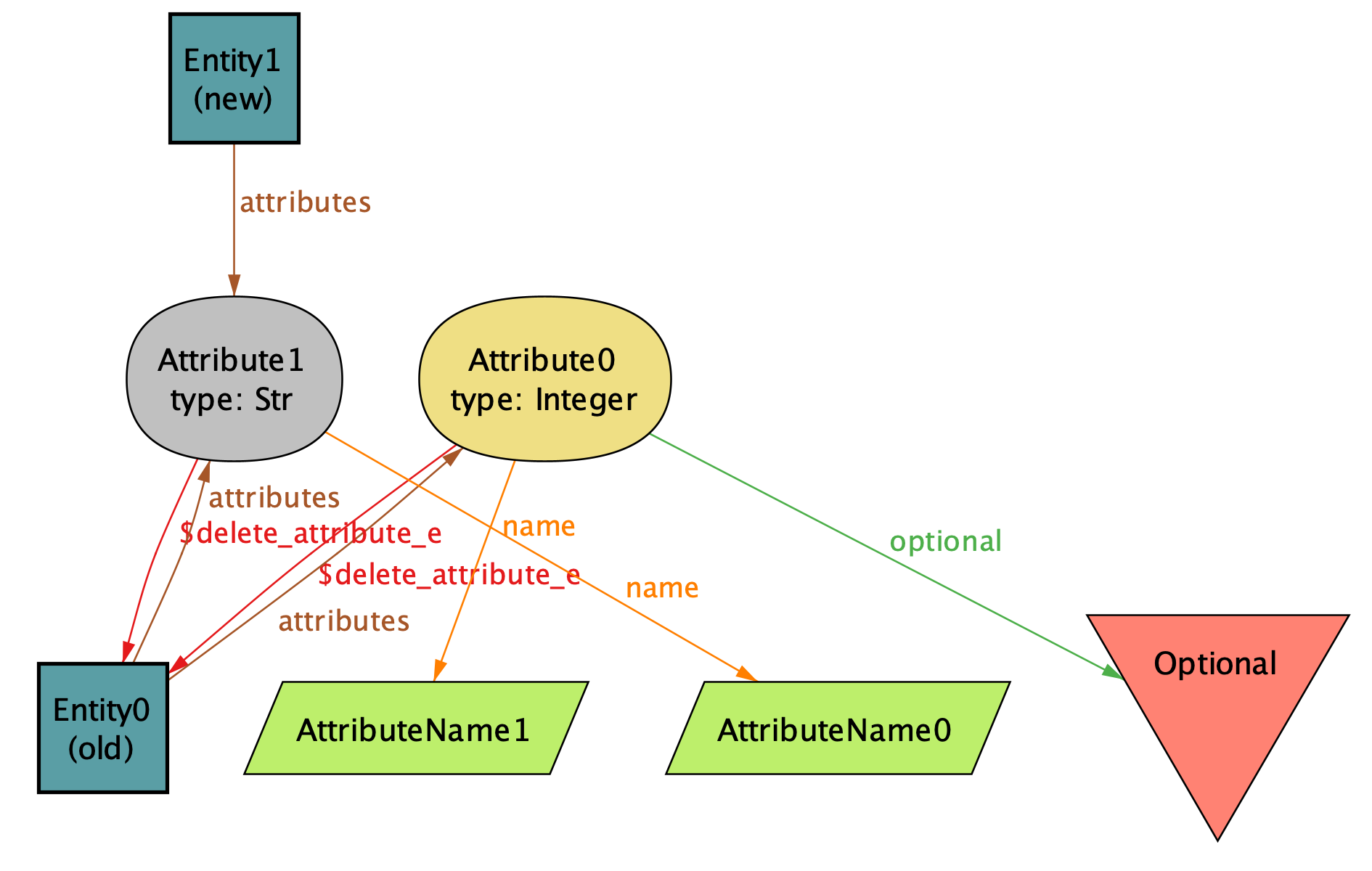
The above is an example of a schema migration of Entity0 that removes its Attribute0. The result entity is called Entity1.
As you may remember, another backward compatible change is adding an optional attribute:
pred add_optional_attribute[e, e2: Entity] {
e != e2
one a: Attribute |
a not in e.attributes && e.attributes + a = e2.attributes && #a.optional = 1
}
pred backward_compatible_change[e, e2: Entity] {
delete_attribute[e, e2] or add_optional_attribute[e, e2]
}Next I need a definition of can_read and transitive:
// can the new code read data encoded with the old code?
pred can_read[new, old: Entity] {
let added = new.attributes - old.attributes |
all a: added |
#a.optional = 1 && a.name not in old.attributes.name
}
assert transitive {
all e1, e2, e3: Entity |
backward_compatible_change[e1, e2] &&
backward_compatible_change[e2, e3] => can_read[e3, e1]
}Now, finally, I can set Alloy on a mission to find a counterexample:
check transitive for 4 but exactly 3 Entity
// Results in:
// Executing "Check transitive for 4 but exactly 3 Entity"
// Solver=sat4j Bitwidth=4 MaxSeq=4 SkolemDepth=1 Symmetry=20 Mode=batch
// 1040 vars. 73 primary vars. 1875 clauses. 10ms.
// . found. Assertion is invalid. 5ms.No surprise here, it did find an example. One of counterexamples found:
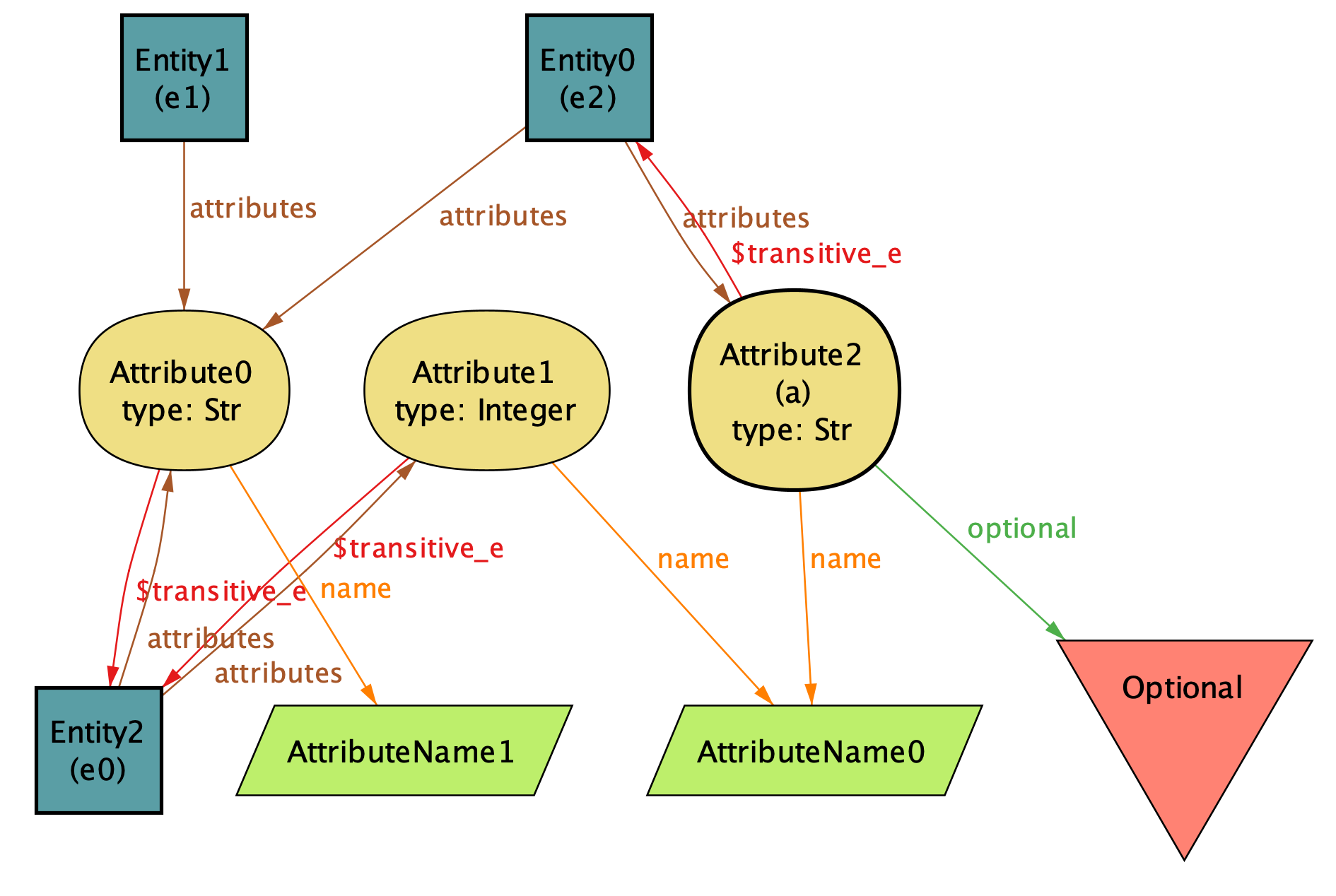
This diagram decyphered:
e0 = {
"fields" : [
{"name" : "AttributeName0", "type" : "int"},
{"name" : "AttributeName1", "type" : "string"}
]
}e1 is e0 minus AttributeName0:
e1 = {
"fields" : [
{"name" : "AttributeName1", "type" : "string"}
]
}e2 is e1 plus AttributeName0:
e2 = {
"fields" : [
{"name" : "AttributeName0", "type" : ["null", "string"]}
{"name" : "AttributeName1", "type" : "string"}
]
}-
e1is backward compatible withe0:AttributeName0present in version 0 will be ignored by reader of version 1
-
e2is backward compatible withe1:- since
AttributeName0is not present in version 1, it will be filled withnullby reader of version 2
- since
-
e2is NOT backward compatible withe0:AttributeName0has been redeclared as optionalstringin version 2, which is incompatible withintin version 0
So the problem is that one can first delete an attribute in one migration (which is backward compatible) to then add the same attribute (which is backward compatible as long as it's optional) with a different type than in the original.
Could this sort of counterexample be found by "just thinking hard enough"? Sure, especially in this case, where the problem space is relatively small. Anyway, it was a nice toy example to play with. Also, some code archeology suggests that authors of schema-registry originally were not aware of this issue, so it's not a trivial example.
The other consequence of this finding is that it is not enough to look just at the current version of the format you're planning to modify. Even a seemingly innocent change, like adding an optional field, might be backward incompatible with some versions in the past.
Don't get me wrong, being compatible with just one version behind is enough in many situations. An example might be two internal services communicating with a protocol with schema. In such cases, compatibility is important just to extend to avoid deployment dependencies. However, you still operate with the assumption that both services will be updated in a matter of days. So, in case of a subsequent update, you can again consider just the current version. Yet, there are as many situations where you do care about more versions, e.g. when you don't control lifetimes of all components involved. Then you need to be mindful about verifying somehow more versions. Also, some formats makes this kind of mistakes harder, e.g., retiring a field in protocol-buffers keeps that field in the protocol definition.
Concluding the exercise, Alloy proved to be a good "thinking enhancer". It's been a tiny adventure, to the next one, hopefully not in a year!